
In our previous blog, we introduced and explained the concept of clean rooms; in particular, Google’s privacy-centric data warehouse solution – Ads Data Hub (ADH). ADH provides a clean room environment where advertisers can continue to use their data modeling capabilities within Google’s walled garden and also acquire insights to help optimize the campaign.
But, ADH can sometimes be tricky as a data warehouse solution. Its privacy-centric nature can make it challenging to get dynamic insights for a live campaign if the objective is to refresh the data after every two or three days. MiQ needed to come up with a solution to get granular insights on a live campaign using ADH data sources and also refresh the data for the insights after a particular frequency. Read on to understand the challenges and how we solved them.
Privacy checks in ADH
Each time we write a query in ADH, we need to keep in mind the three privacy checks provided by ADH:
Static Privacy Check
This helps with the immediate noticeable privacy concern in our queries even before we can run it using ADH UI or API (instant exception thrown).
Aggregation Privacy Check
- This ensures that every row from the ADH query result includes enough users to protect the end-user privacy.
- For most queries, we only receive aggregated data on 50 or more users. However, queries that retrieve clicks and conversions can be used to aggregate ten or more users. Any row that doesn’t follow the aggregation check gets filtered out.
Difference check
- This prevents us from gathering information about individual users by running the same query multiple times for a close or overlapping date range thereby preventing comparison of the data from the multiple sets of users
- So when any query tries to aggregate the same set of users in simultaneous jobs at a particular level (Let’s say, date level aggregate), then a few rows may get filtered out in our current job and may not appear in the result set unless we mention the ‘Filtered Row Summary’ for our query.
Since Ads Data Hub writes the results to a BigQuery table, sometimes we may want to transform those results into a presentable format before sharing them with our teams/clients. This can be done by:
- Either, directly sharing the BigQuery table if the output data from the ADH query already serves the desired granularity.
- Or, by visualizing the data from the BigQuery table in a Data Visualization or Business Intelligence Tool.
This is where Google Data Studio (GDS) comes in. It serves as a great data visualization tool and is part of the Google Marketing Platform (GMP). It helps in building interactive dashboards, and customized, beautiful reporting. We use GDS to track critical KPIs for clients, visualize trends, and compare performance over time.
How can you gain insights on a campaign using ADH?
Running an ADH query once & getting results in BigQuery

Figure 1: Ideal flow for data visualization from ADH

Figure 2: BQ Table for insights on line items (Job 1)
Let’s start by understanding a basic flow (Figure 1). Imagine you are an ad agency running a campaign for an advertising client, and their DV360 account is linked to your ADH account. For the campaign, you have created a single insertion order (IO) with a set of 5 line items and you want to get insights on all the 5 line items (Figure 2) by writing an ADH query. The ADH – DV360 data sources could be used as shown in Figure 3 to help create the required query.

Figure 3: ADH Query
It’s always a good practice to mention a Filtered Row Summary (FRS) before we execute our query. In this case, to specify the FRS, ‘line_item’ and ‘line_item_id’ can be kept as ‘ConstantConstant’, and ‘impressions’, ‘conversions’, and ‘media_cost’ can be kept as ‘SumSum’. Once your ADH query execution is completed and the data is dumped in BigQuery, it can be easily rendered in the GDS dashboard using the BigQuery connector.
This was quite straightforward as it was a one-time job, and if you are lucky none of the rows will get filtered out due to aggregation checks.
How can you refresh data in the BigQuery table for dynamic insights?
Running an ADH query with a refresh frequency & getting results in BigQuery
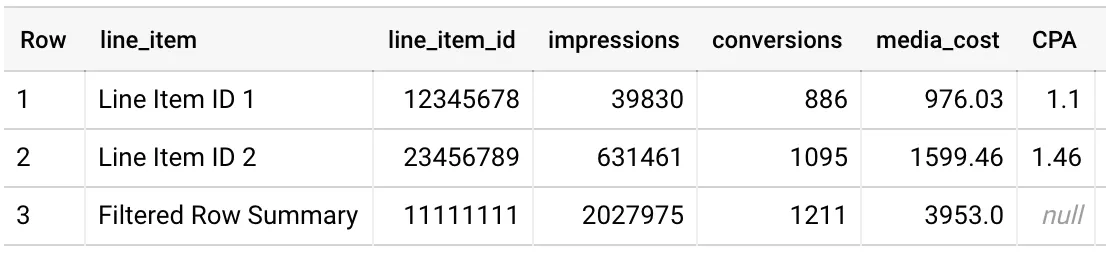
Figure 4: BQ Table for insights on line items (Job 2)
Now let’s consider another scenario where we need to schedule the previously explained ADH query and pull the latest data in the BigQuery table.
Imagine you run the same query the next day and you may get the result something similar to Figure 4. Now if we try to acquire insights using this BigQuery table, it will be quite misleading. What went wrong in your second run where three of the line items didn’t show up individually and instead were filtered?
This happens because ADH isn’t a straightforward data warehouse solution where the data could just be queried and retrieved. In the second job scenario, due to difference check, ADH may have detected some vulnerabilities on the level of individual users when comparing a job’s results to previous results, as there may be a large number of overlapping users, and so, a few line items get filtered out. Common blockers users face at this point:
- Data is filtered out at each subsequent run, leaving you with few or zero rows in the output table.
- If the same query is run multiple times, the user may get blocked from running those queries for some time ( usually six-seven hours, which could increase case-wise).
How did we work around this limitation without sacrificing privacy-centricity?
We understand the limitations of retrieving data from the same ADH query by running it multiple times. So, what can be done to get near real-time data for insights on a live campaign with a refresh frequency of two or three days and get the most data out from the filtered row summary?

We tried solving this limitation by including a separate data flow architecture (Figure 5) in our workflow from the second run onwards.
- Let’s start by terming the BiqQuery table from the first run, as the Master Table. We start by backing up the Master Table from the first run or the previous run in a new Table, called Backup Table.
- Next, we continue to run the same ADH query with a start date as the Day 1 of the campaign and the end date being the last valid day in the calendar (yesterday), which will populate the result in a new table, called Temporary Table.
- Then, we will truncate the complete Master table and write all the rows from the Temporary Table in it.
- The next step is to insert rows from the Backup Table with any unique rows (unique line items in our case) which may have been filtered out in the Temporary Table due to privacy checks.
Now, the final Master table in the second run may look something similar to Figure 6, which has backfilled the missing line items.

Figure 6: BQ table insight on line items as per the new architecture
Why not just group the data and sum up the dimensions?
People may tend to ask, why not perform a union of the table from the current run (running the query for only fresh days instead of running it from Day 1) and the previous run and then the group at ‘line_item’ and ‘line_item_id’ level and simply add up all dimensions and recalculate the metrics?
The explanation is quite simple.
Let’s say ‘Line Item ID 3’ gets filtered in the second run. So that particular data will be part of the Filtered Row Summary. Then the same line-item reappears in the third run, following which you may just add up the dimensions like ‘impressions’, ‘conversions’, and ‘media_cost’. Now, this data will be misleading because the data for that line item doesn’t include figures from the second run. The idea of just grouping the data and summing up the dimensions is not a good one.

Figure 7: BQ table insights on date-level
Though the above argument for running the ADH query for the last one or two days instead of running it from Day one of the campaign may work better when we are trying to get insights for a particular date.
If we already have an ADH query and a master table with date level trends from 1st-3rd January 20211, but we want to get the data for the 4th & 5th January, then we could try running the ADH query for only those two days and then merge the result to the master table (Figure 7).
Then, the date level insights would also help us with some other level (eg: ‘day of week’ level) insights.
The solution

Figure 8: Data Studio Dashboard using the master table.
Using the above-suggested solution in all our future runs can make sure all the new rows are updated, and rows that aren’t updated will have the data from the previous runs. This gives us another insight into the rows, which aren’t updating for a long time that the line items may be performing poorly or may have been deactivated. The above flow will help in getting the most details by running the same ADH query with a particular frequency. Even if the rows are filtered out we would have a snapshot of old data to be shown in the dashboard.
The master table (Figure 6) which gets refreshed after each run can be used in the Data Studio dashboard (Figure 8) for tracking clients’ KPIs and visualizing trends. Each time the master table is refreshed we can refresh the dashboard to render the fresh data (highlighted in red). This will allow for important decisions to be made during the run of the campaign to optimize, improve performance, and, ultimately maximize profits.
Can you see yourself innovating in clean rooms like ADH for leading advertising brands? Check out our life at MiQ page.
Want more tech talk? Our Medium blog covers future-shaping data science and analytics innovation from the MiQ team.